
Simulation of Core Flooding with Predicted Oil and Water RelativePermeabilities Using Bagging, Boosting, and Stacking MachineLearning Techniques
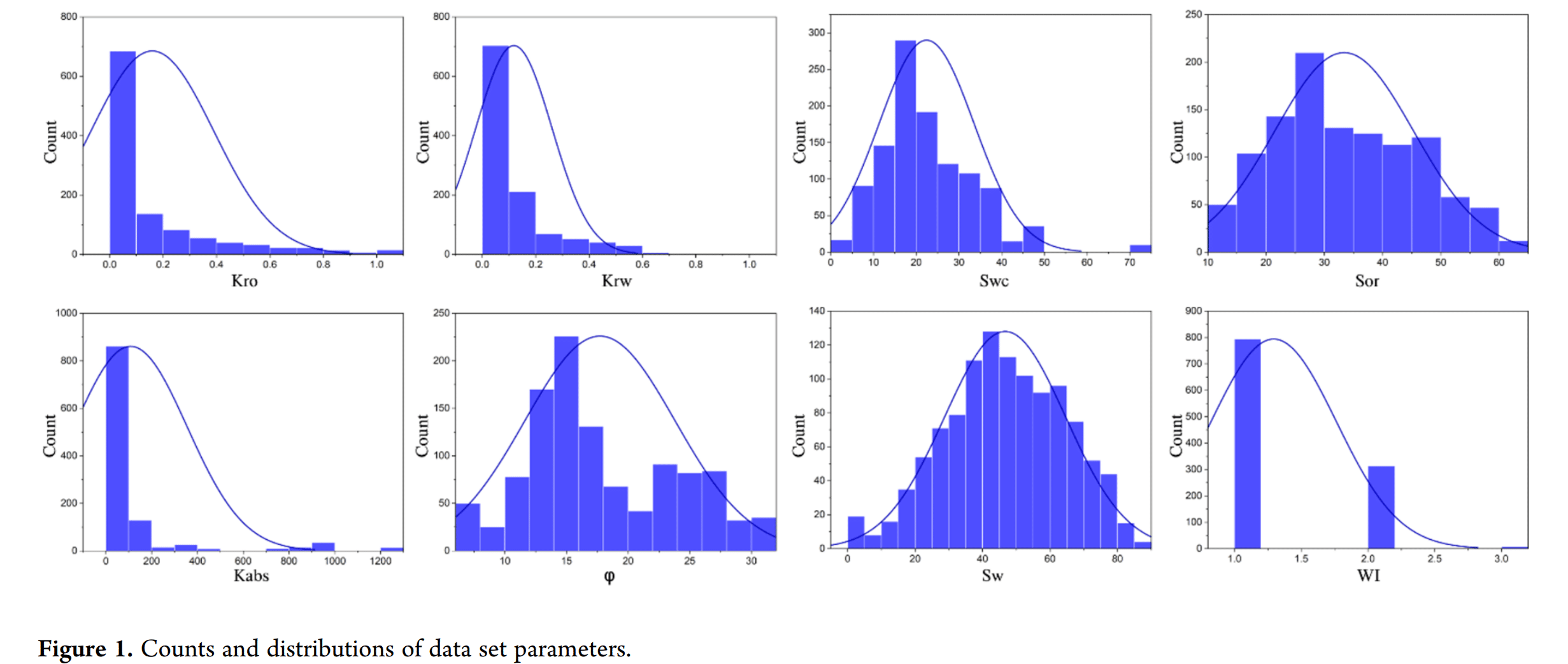
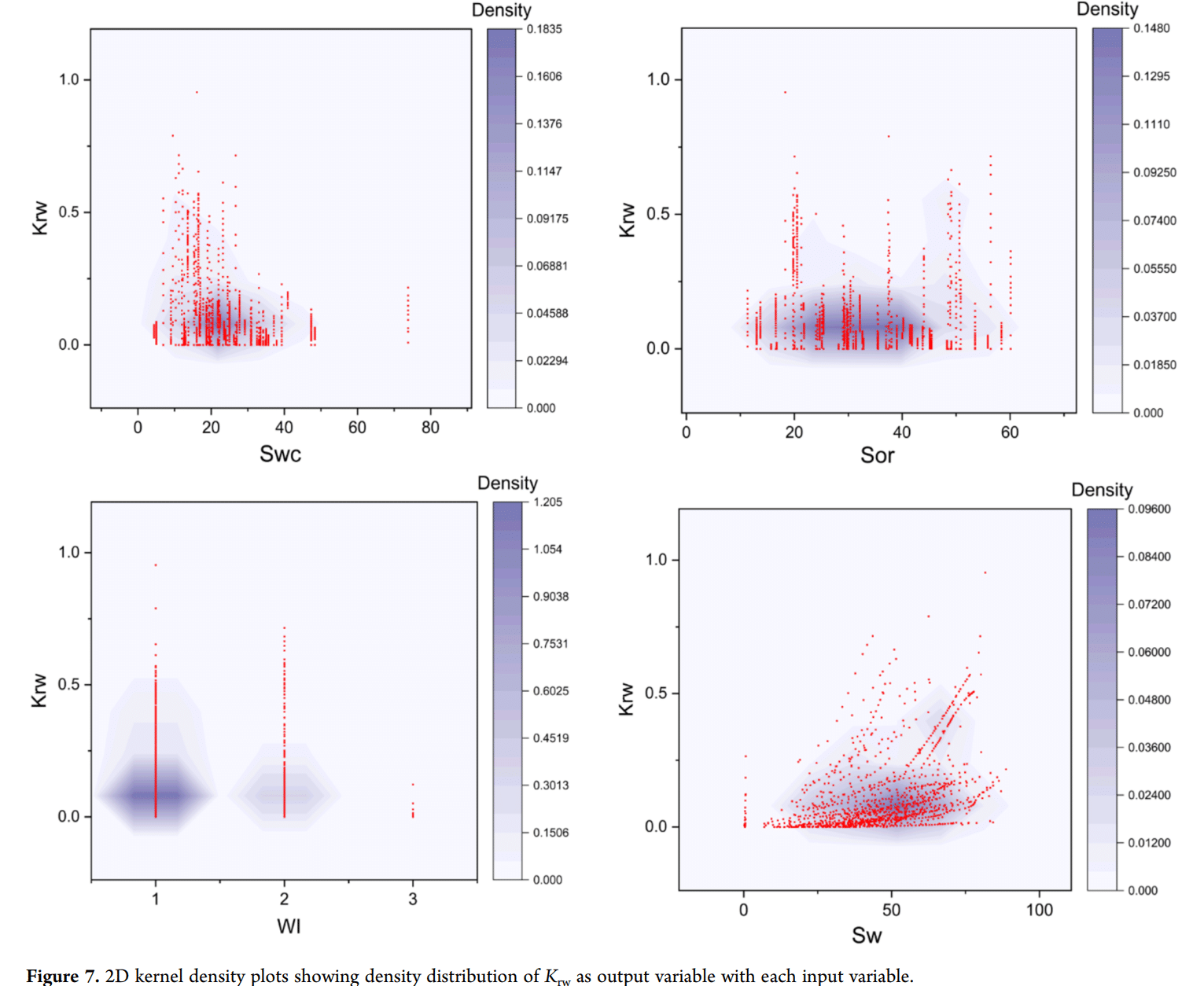
油田开发和管理需要油藏模拟,其参数包括相对渗透率曲线。然而,经验测量相对渗透率可能既繁琐又耗时,而能够预测它们的机器学习模型通常难以使用。本研究提出了使用预测的油水相对渗透率进行岩心驱替实验的模拟,以及用于预测这些相对渗透率的简单监督机器学习模型。针对每种相对渗透率开发了一个预测模型,这些模型基于包含超过1000个数据点的数据集,并使用了Bagging、Boosting和Stacking技术(随机森林、自适应增强和线性回归算法)。模型评估显示了高决定系数和小均方误差,表明模型具有准确性。此外,k折交叉验证的评估指标接近模型的指标,表明它们能够泛化且几乎没有过拟合。实验和模拟的采收因子分别为60.05%和59.45%,历史拟合质量指数为95%。这些发现验证了机器学习模型的预测作为经验测量值的可行替代方案。
CMG软件应用情况
本研究使用了CMG软件(Builder、STARS和Results)来模拟岩心驱替实验。CMG软件用于构建模型、运行模拟以及可视化结果。研究中通过机器学习模型预测的相对渗透率曲线被输入到CMG的Builder中,用于绘制和平滑相对渗透率曲线。最终,使用STARS运行模拟,并通过Results查看结果。模拟结果显示,使用预测的相对渗透率曲线进行的岩心驱替实验与实验结果匹配良好,验证了机器学习模型预测的可靠性。
结论
- 本研究提出了一种使用机器学习预测的油水相对渗透率进行岩心驱替实验模拟的方法。所有模型输入参数均可在实验室中测量。
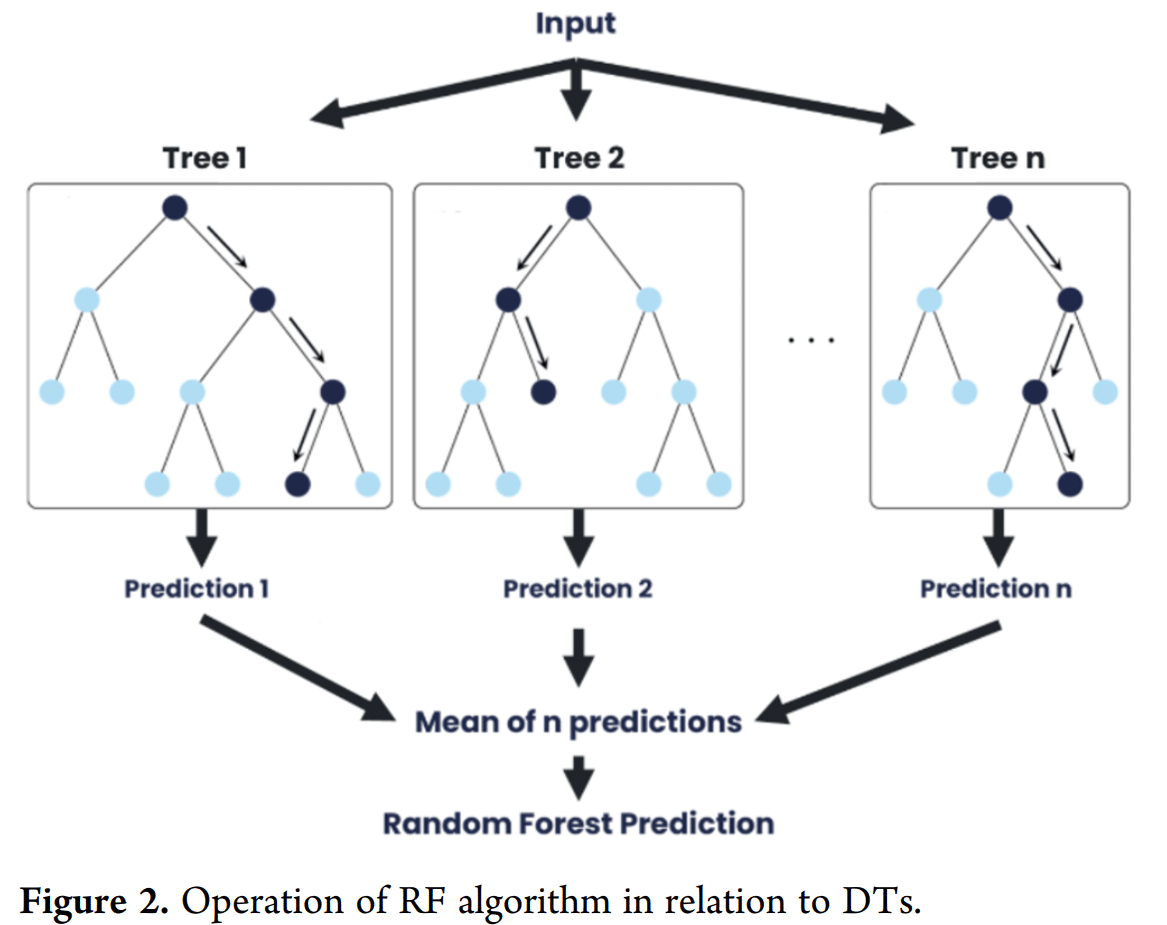
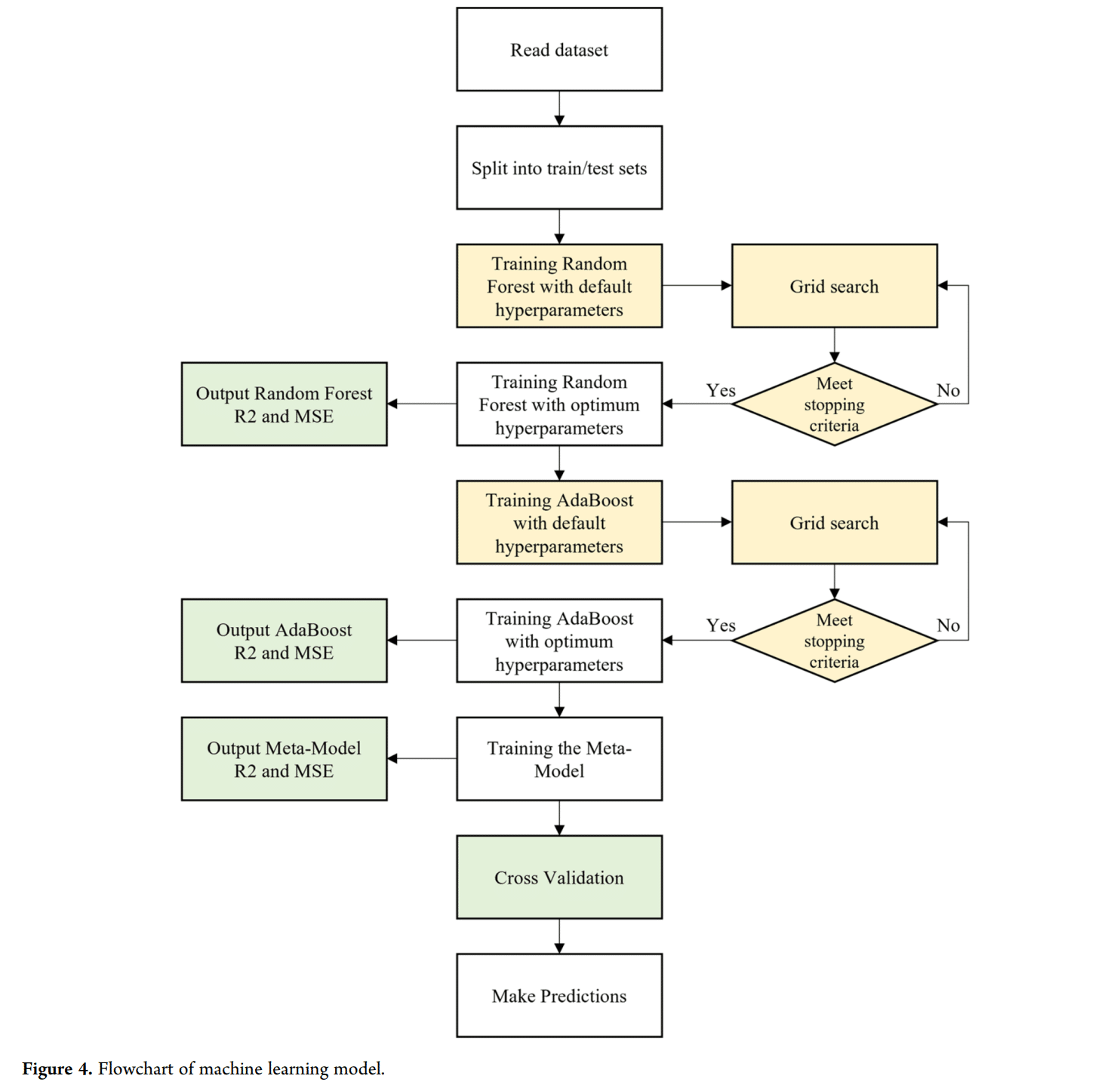
- 机器学习模型基于超过1000个数据点的数据集,并结合了Bagging、Boosting和Stacking技术(使用随机森林、自适应增强和线性回归算法)。Python及其scikit-learn库被用于开发Stacked RF-AdaBoost模型,使其更易于被机器学习初学者使用。
- 模型预测与数百个未见实验数据点的值进行了比较,Kro和Krw预测的决定系数(R-squared)分别为0.9563和0.9810,均方误差(MSE)分别为0.0016和0.0004。模型表现出强大的泛化能力,这通过模型与交叉验证的评估指标之间的微小差异得到了支持。
- 使用预测的相对渗透率曲线进行的岩心驱替实验模拟与实验结果匹配良好,实验和模拟的采收因子分别为60.05%和59.45%,历史拟合质量指数为95%。因此,该方法在缺乏经验测量值时为研究人员提供了一种有效的替代方案。
- 尽管模型表现令人满意,但本研究使用的小型数据集限制了模型的进一步优化。未来的研究可以通过使用更大的数据集来进一步改进模型。
作者单位
日本秋田大学国际资源科学研究生院地球资源工程与环境科学系

Abstract
Oil field development and management require oil reservoir simulations, whose parameters include relative permeability curves. However, empirical measurement of relative permeabilities can be arduous and time-consuming, and the machine learning models that can predict them are often difficult to use. This study presents the simulation of a core flooding experiment using predicted oil and water relative permeabilities and the simple supervised machine learning models used to predict them. A model was developed for predicting each relative permeability. These models were based on a data set containing over 1000 data points and bagging, boosting, and stacking techniques (random forest, adaptive boosting, and linear regression algorithms). Model evaluation showed a high coefficient of determination and a small mean squared error, demonstrating model accuracy. Furthermore, the evaluation metrics of k-fold cross-validation were close to those of the models, indicating they could generalize and had minimal overfitting. The experimental and simulated oil recovery factors were 60.05 and 59.45%, respectively, with a history match quality index of 95%. These findings validated the machine learning models’ predictions as viable alternatives that researchers can use when lacking empirically
